
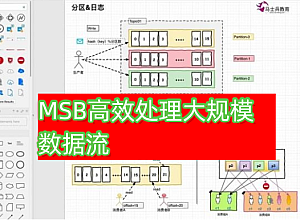

这门课程为我提供了对Apache Kafka企业集群分布式流处理服务的全面指南,让我能够深入理解并高效应用它来处理大规模的数据流。在学习的过程中,我深入探究了Kafka的基本概念与原理,这些理论知识为我后续的实践操作打下了坚实的基础。
通过课程的实践环节,我熟练掌握了Kafka集群的安装与配置,学会了如何创建主题和分区,以及如何进行数据的生产和消费。这些基础操作技能的掌握,让我能够在实际工作场景中灵活应对各种需求。
在掌握了基础操作后,我进一步学习了如何利用Kafka Connect和Kafka Streams构建实时数据处理流程。Kafka Connect帮助我轻松连接各种数据源和目标,实现数据的高效传输与同步。而Kafka Streams则赋予我编写复杂流处理应用的能力,使我能够根据不同的业务场景需求,处理和转换数据流。
除了理论学习,课程还提供了丰富的实践练习和案例研究,让我有机会将所学知识应用于实际项目中。通过实践,我不仅学会了如何优化Kafka集群的性能和可扩展性,还掌握了监控和管理集群的技能,确保集群的稳定运行,并能够迅速发现并解决潜在问题。
此外,课程还详细介绍了Kafka生态系统中的其他重要组件和工具,如Kafka Connect、Kafka Streams和Schema Registry等。我对这些工具的使用和集成有了更深入的了解,这使我能够构建更复杂、功能更强大的数据流处理解决方案,满足企业不断变化的业务需求。
通过这门课程的学习,我不仅对Apache Kafka有了全面而深入的了解,还掌握了丰富的实践经验和技能。这些知识和能力将为我未来的职业发展提供有力的支持,使我能够在大数据处理领域取得更好的成就。



















